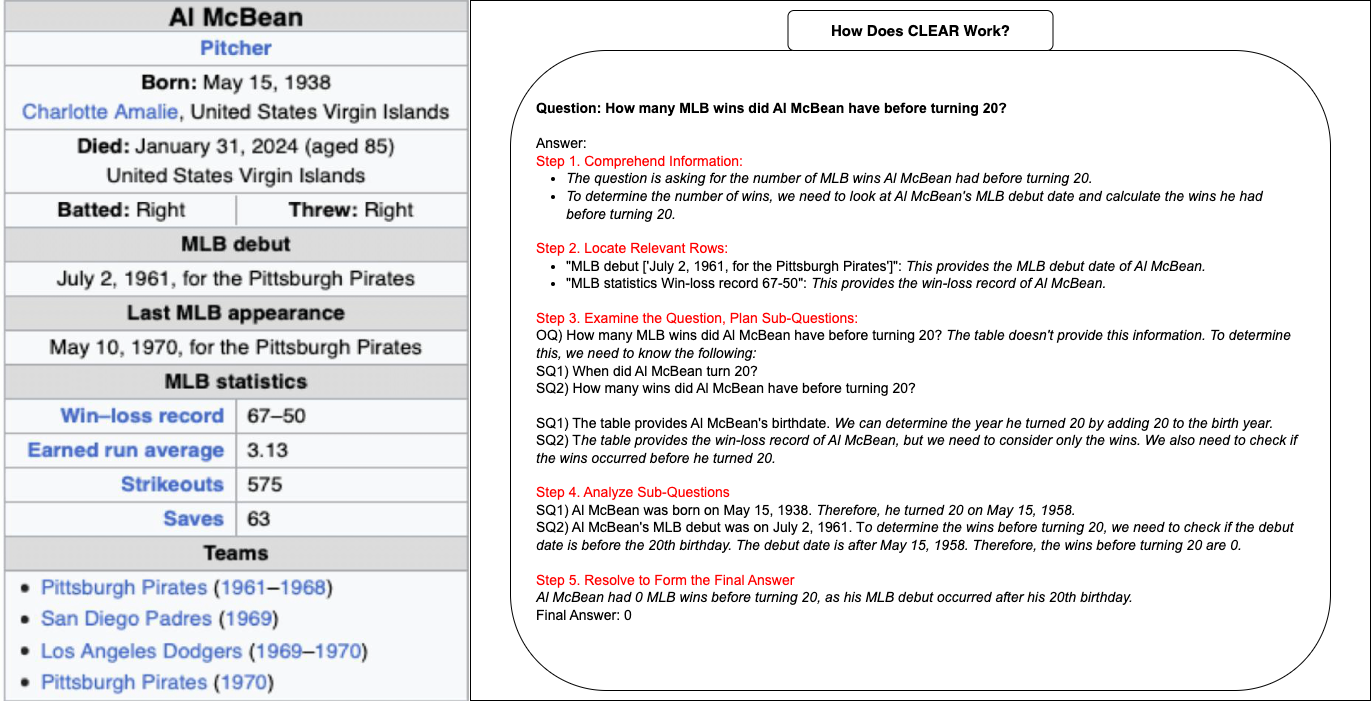
C.L.E.A.R Prompting: A Structured Approach to Complex Question Answering
To enhance the accuracy of large language models (LLMs) in handling temporal reasoning over semi-structured data, we introduce the C.L.E.A.R prompting framework. This method systematically reduces errors such as hallucinations, incomplete evidence extraction, and misinterpretations by breaking down the reasoning process into five structured steps:
- Comprehend : Understand the question by applying domain knowledge, correctly interpreting its temporal components, and identifying key details.
- Locate : Extract only the relevant rows from the data table, ensuring that all necessary evidence is collected to answer the question accurately.
- Examine : Decompose complex queries into manageable sub-questions, making temporal calculations clearer and reducing reasoning errors.
- Analyze : Answer each sub-question using extracted evidence, applying logical reasoning and ensuring consistency with the available data.
- Resolve : Synthesize the answers from the sub-questions into a final response, ensuring clarity, correctness, and logical coherence.
The C.L.E.A.R approach provides a structured, step-by-step method that improves LLMs’ reasoning capabilities, minimizing common errors and enhancing reliability in complex question answering.
.png)